
Redis与MQ在项目中的运用

Redis与MQ在项目中的运用
SoniaChen1、Redis与MQ在项目中的运用!
Redis应用场景-缓存系统
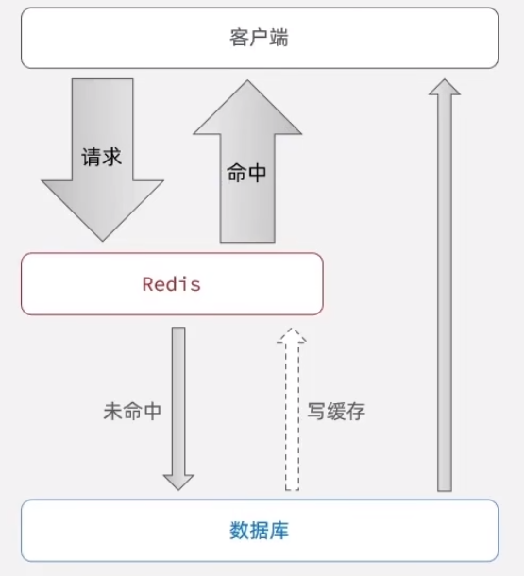
Redis最主要的还是做缓存,一般的方案下就是把热点数据(访问频次高)的数据放入Redis缓存,用Redis的高性能去避免MySQL数据的。这种方案一般的做法都会有兜底方案,就是数据在Redis中没有话,还是会去访问MySQL然后再把数据同步到Redis缓存。
Redis应用场景-排行榜、计数器
1、Redis提供的incr方法做计数器(点赞、关注数之类)
import redis.clients.jedis.Jedis;
public class RedisCounter {
private Jedis jedis;
public RedisCounter() {
// 连接到 Redis
this.jedis = new Jedis("localhost", 6379);
}
// 用户点赞
public void likePost(String postId) {
jedis.incr("post:" + postId + ":likes");
}
// 用户关注
public void followUser(String userId) {
jedis.incr("user:" + userId + ":followers");
}
public static void main(String[] args) {
RedisCounter counter = new RedisCounter();
// 示例:用户点赞
counter.likePost("post1");
counter.likePost("post1");
// 示例:用户关注
counter.followUser("user1");
// 输出点赞数和关注者数
System.out.println("Post1 Likes: " + counter.jedis.get("post:post1:likes"));
System.out.println("User1 Followers: " + counter.jedis.get("user:user1:followers"));
// 关闭连接
counter.jedis.close();
}
}2、Redis提供的有序集合(sorted set)可以用来创建排行榜
import redis.clients.jedis.Jedis;
import java.util.Set;
public class RedisLeaderboard {
private Jedis jedis;
public RedisLeaderboard() {
// 连接到 Redis
this.jedis = new Jedis("localhost", 6379);
}
// 用户点赞时更新排行榜
public void likePost(String postId, String userId) {
// 假设每个点赞增加用户的分数
jedis.zincrby("post_rank", 1, userId);
}
// 获取前 N 名用户
public Set<String> getTopUsers(int n) {
return jedis.zrevrange("post_rank", 0, n - 1);
}
public static void main(String[] args) {
RedisLeaderboard leaderboard = new RedisLeaderboard();
// 示例:用户点赞
leaderboard.likePost("post1", "user1");
leaderboard.likePost("post1", "user2");
leaderboard.likePost("post1", "user1"); // user1 再次点赞
// 获取前 2 名用户
Set<String> topUsers = leaderboard.getTopUsers(2);
System.out.println("Top Users: " + topUsers);
// 关闭连接
leaderboard.jedis.close();
}
}Redis应用场景-共享session
多台应用服务器可以将用户的session存储在Redis中(缓存+过期机制)
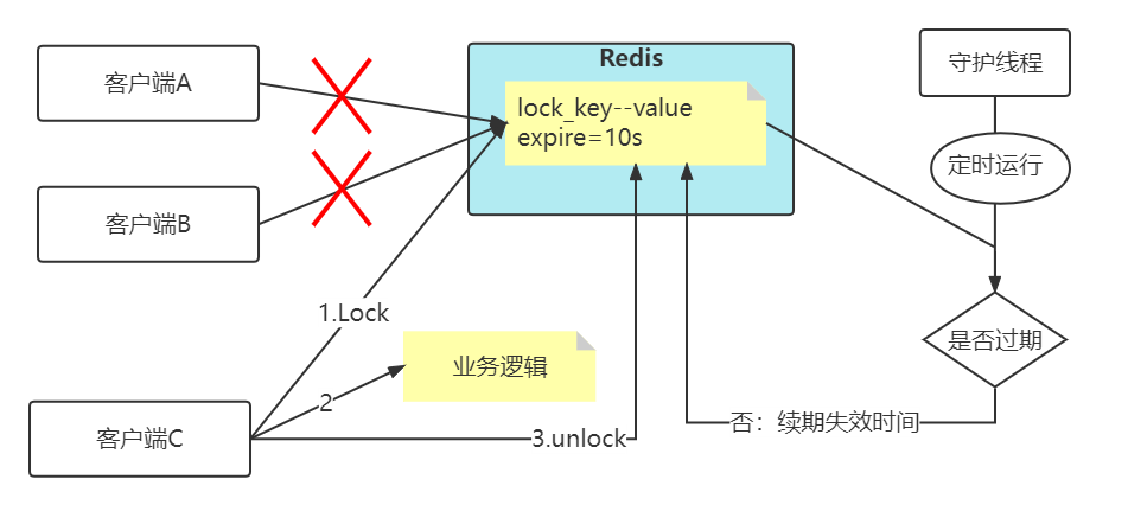
Redis应用场景-分布式锁
Redisson的API介绍:
https://github.com/redisson/redisson/wiki/8.-分布式锁和同步器#84-红锁redlock
分布式锁加入过期时间+加入看门狗
加锁时,先设置一个过期时间,然后我们开启一个「守护线程」,定时去检测这个锁的失效时间,如果锁快要过期了,操作共享资源还未完成,那么就自动对锁进行「续期」,重新设置过期时间。
这个守护线程我们一般也把它叫做「看门狗」线程。
Redis应用场景-布隆过滤器
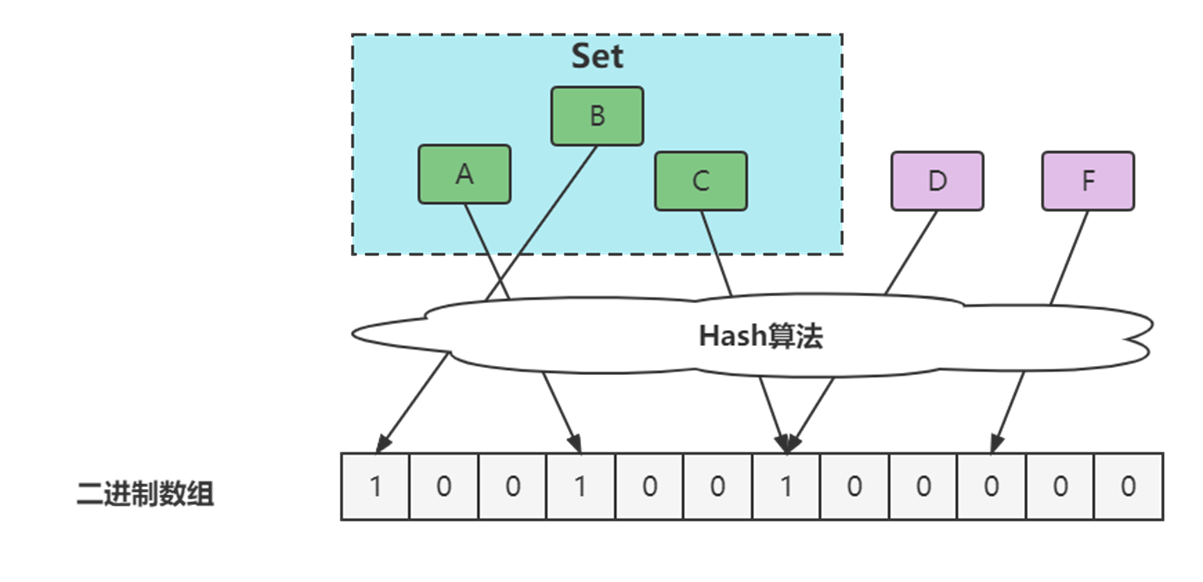
1970 年布隆提出了一种布隆过滤器的算法,用来判断一个元素是否在一个集合中。这种算法由一个二进制数组和一个 Hash 算法组成。
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
实际上,布隆过滤器广泛应用于网页黑名单系统、垃圾邮件过滤系统、爬虫网址判重系统等,Google 著名的分布式数据库 Bigtable 使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的IO次数,Google Chrome浏览器使用了布隆过滤器加速安全浏览服务。
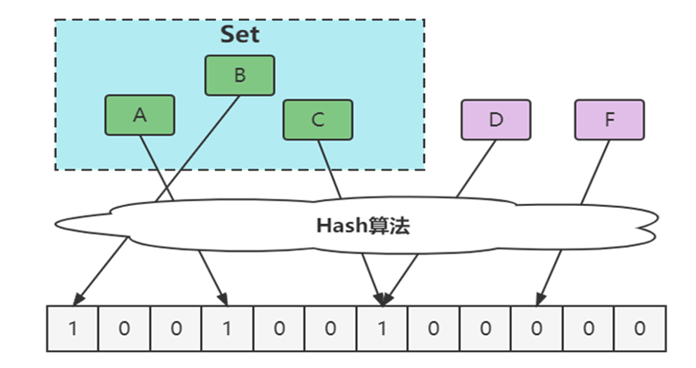
布隆过滤器的误判问题
Ø通过hash计算在数组上不一定在集合
Ø本质是hash冲突
Ø通过hash计算不在数组的一定不在集合(误判)
优化方案
增大数组(预估适合值)
增加hash函数
Redis应用场景-Bitmap海量用户存储
1、目前有10亿数量的自然数,乱序排列,需要对其排序。限制条件-在32位机器上面完成,内存限制为 2G。如何完成?
- 使用一个大小为 1,000,000,000 的 Bitmap(每个自然数对应一个位)。
- 将每个自然数的位设置为 1,表示该数存在。
- 然后,可以遍历 Bitmap,按顺序输出所有存在的自然数。
由于内存限制为 2G,一个大小为 1,000,000,000 的 Bitmap 在 Redis 中大约占用 119.2 MB 的内存
2、如何快速在亿级黑名单中快速定位URL地址是否在黑名单中?(每条URL平均64字节)
把URL做Hash值计算,然后将其映射到 Bitmap。
- 计算 URL 的哈希值,并将对应的位设置为 1。
- 检查 URL 是否在黑名单中,只需查看对应的位是否为 1。
3、需要进行用户登陆行为分析,来确定用户的活跃情况?
可以使用 Bitmap 来记录用户的登录状态,用户 ID 作为位的索引。
- 每次用户登录时,将对应的位设置为 1。
- 可以通过位计数来获取活跃用户的数量。
Redis应用场景-GEO地图
GEO
Redis 3.2版本提供了GEO(地理信息定位)功能,支持存储地理位置信息用来实现诸如附近位置、摇一摇这类依赖于地理位置信息的功能。
地图元素的位置数据使用二维的经纬度表示,经度范围(-180, 180],纬度范围(-90,90],纬度正负以赤道为界,北正南负,经度正负以本初子午线(英国格林尼治天文台) 为界,东正西负。
业界比较通用的地理位置距离排序算法是GeoHash 算法,Redis 也使用GeoHash算法。GeoHash算法将二维的经纬度数据映射到一维的整数,这样所有的元素都将在挂载到一条线上,距离靠近的二维坐标映射到一维后的点之间距离也会很接近。当我们想要计算「附近的人时」,首先将目标位置映射到这条线上,然后在这个一维的线上获取附近的点就行了。
在 Redis 里面,经纬度使用 52 位的整数进行编码,放进了 zset 里面,zset 的 value 是元素的 key,score 是 GeoHash 的 52 位整数值。
操作命令
增加地理位置信息
geoadd key longitude latitude member [longitude latitude member …J
longitude、latitude、member分别是该地理位置的经度、纬度、成员,例如下面有5个城市的经纬度。
城市 经度 纬度 成员
北京 116.28 39.55 beijing
天津 117.12 39.08 tianjin
石家庄 114.29 38.02 shijiazhuang
唐山 118.01 39.38 tangshan
保定 115.29 38.51 baoding
cities:locations是上面5个城市地理位置信息的集合,现向其添加北京的地理位置信息:
geoadd cities :locations 116.28 39.55 beijing
返回结果代表添加成功的个数,如果cities:locations没有包含beijing,那么返回结果为1,如果已经存在则返回0。
如果需要更新地理位置信息,仍然可以使用geoadd命令,虽然返回结果为0。geoadd命令可以同时添加多个地理位置信息:
geoadd cities:locations 117.12 39.08 tianjin 114.29 38.02shijiazhuang 118.01 39.38 tangshan 115.29 38.51 baoding
获取地理位置信息
geopos key member [member …]下面操作会获取天津的经维度:
geopos cities:locations tianjin1)1)“117.12000042200088501”
获取两个地理位置的距离。
geodist key member1 member2 [unit]
其中unit代表返回结果的单位,包含以下四种:
m (meters)代表米。
km (kilometers)代表公里。
mi (miles)代表英里。
ft(feet)代表尺。
下面操作用于计算天津到北京的距离,并以公里为单位:
geodist cities : locations tianjin beijing km
获取指定位置范围内的地理信息位置集合
georadius key longitude latitude radius m|km|ft|mi [withcoord][withdist]
[withhash][COUNT count] [ascldesc] [store key] [storedist key]
georadiusbymember key member radius m|km|ft|mi [withcoord][withdist]
[withhash] [COUNT count][ascldesc] [store key] [storedist key]
georadius和georadiusbymember两个命令的作用是一样的,都是以一个地理位置为中心算出指定半径内的其他地理信息位置,不同的是georadius命令的中心位置给出了具体的经纬度,georadiusbymember只需给出成员即可。其中radius m | km |ft |mi是必需参数,指定了半径(带单位)。
这两个命令有很多可选参数,如下所示:
withcoord:返回结果中包含经纬度。
withdist:返回结果中包含离中心节点位置的距离。
withhash:返回结果中包含geohash,有关geohash后面介绍。
COUNT count:指定返回结果的数量。
asc l desc:返回结果按照离中心节点的距离做升序或者降序。
store key:将返回结果的地理位置信息保存到指定键。
storedist key:将返回结果离中心节点的距离保存到指定键。
下面操作计算五座城市中,距离北京150公里以内的城市:
georadiusbymember cities:locations beijing 150 km
获取geohash
geohash key member [member ...]Redis使用geohash将二维经纬度转换为一维字符串,下面操作会返回beijing的geohash值。
geohash cities: locations beijing
字符串越长,表示的位置更精确,geohash长度为9时,精度在2米左右,geohash长度为8时,精度在20米左右。
两个字符串越相似,它们之间的距离越近,Redis 利用字符串前缀匹配算法实现相关的命令。
geohash编码和经纬度是可以相互转换的。
删除地理位置信息
zrem key member
GEO没有提供删除成员的命令,但是因为GEO的底层实现是zset,所以可以借用zrem命令实现对地理位置信息的删除。
MQ应用场景-异步解耦

1、灵活适应业务的快速增长:通过MQ的异步化设计,可以灵活高效的适应因业务快速发展而带来的变化,如新增业务系统。
2、高可用松耦合架构设计:通过上、下游业务系统的松耦合设计,即便下游子系统(如物流、积分等)出现不可用甚至宕机,都不会影响到核心交易系统的正常运转
MQ应用场景-削峰填谷
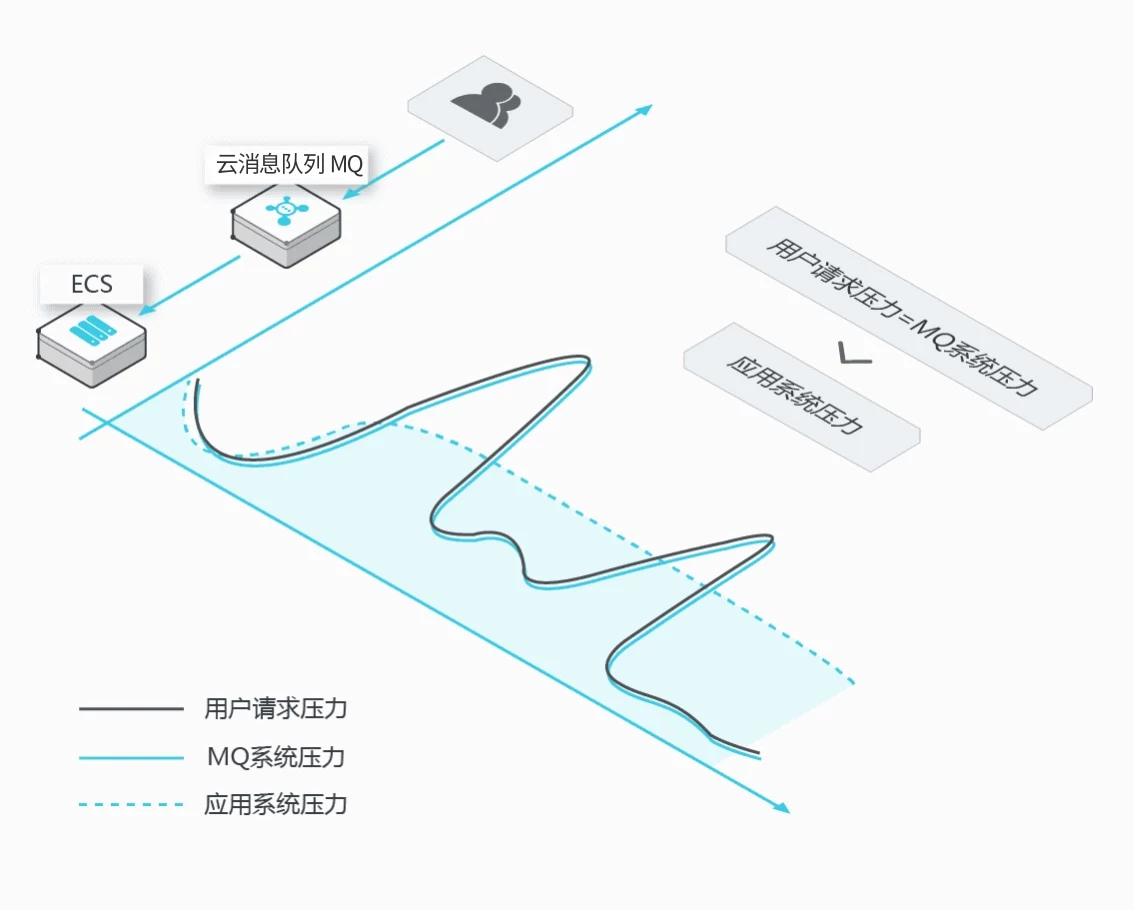
秒杀、抢红包、企业开门红等大型活动时皆会带来较高的流量脉冲,或因没做相应的保护而导致系统超负荷甚至崩溃,或因限制太过导致请求大量失败而影响用户体验。用MQ的削峰填谷是解决该问题的有效方式。
1、超高流量脉冲处理能力:MQ 超高性能的消息处理能力可以承接流量脉冲而不被击垮,在确保系统可用性同时,因快速有效的请求响应而提升用户的体验
2、海量消息堆积能力:确保下游业务在安全水位内平滑稳定的运行,避免超高流量的冲击
3、合理的成本控制:削峰填谷可控制下游业务系统的集群规模,从而降低投入成本
RocketMQ应用场景-分布式事务消息
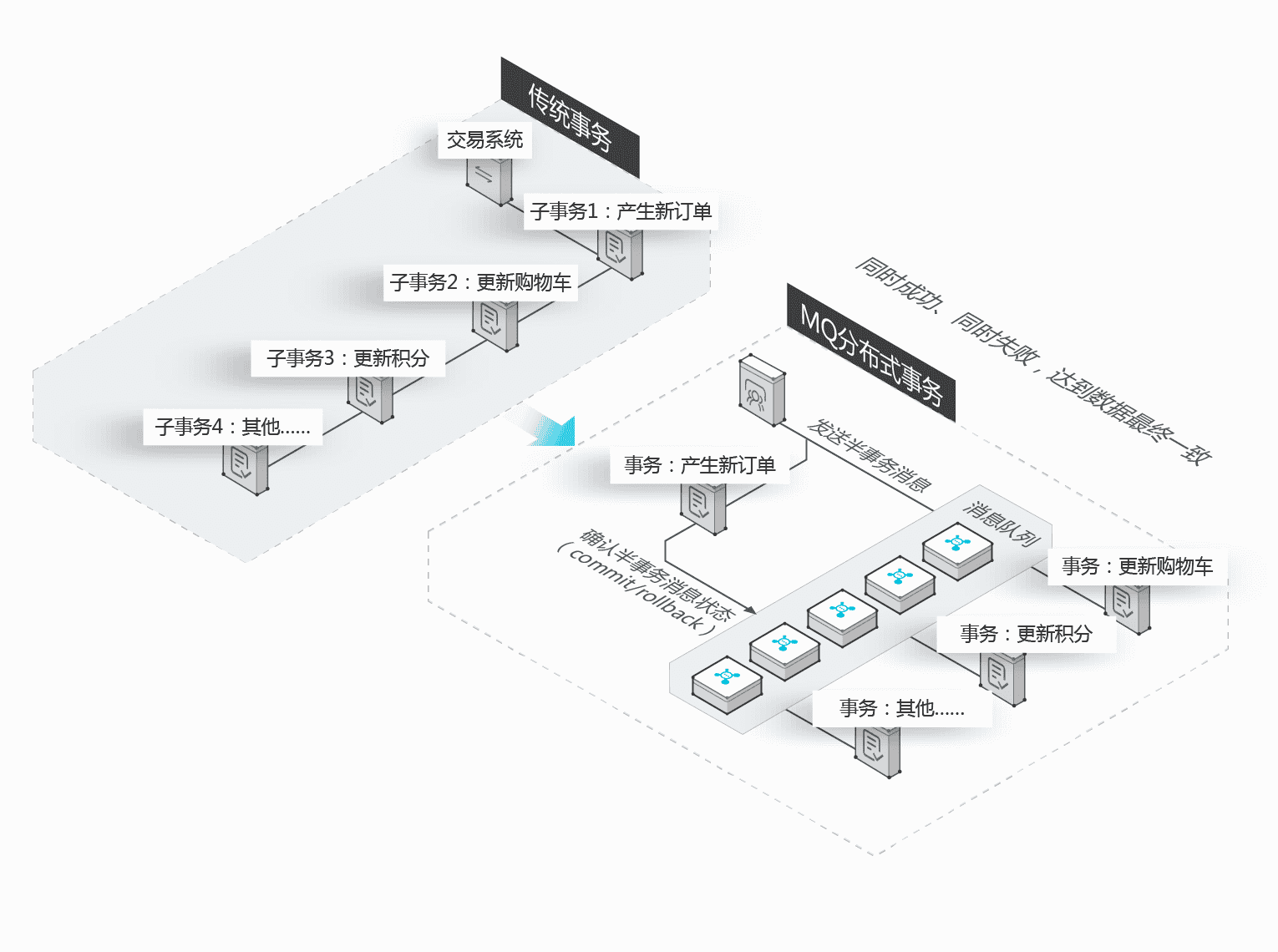
**传统事务:**多个系统或者应用组件之间的业务处理会耦合到一个大事务中,响应时间长,业务链路长从而影响系统的整体性能和可用性,甚至引起系统崩溃
**RocketMQ分布式事务:**将核心链路业务与可异步化处理的分支链路进行拆分,将大事务拆分成小事务,减少系统间的交互,既高效又可靠;RocketMQ 的可靠传输与多副本技术能确保消息不丢失。
RocketMQ/Kafka-流式数据处理
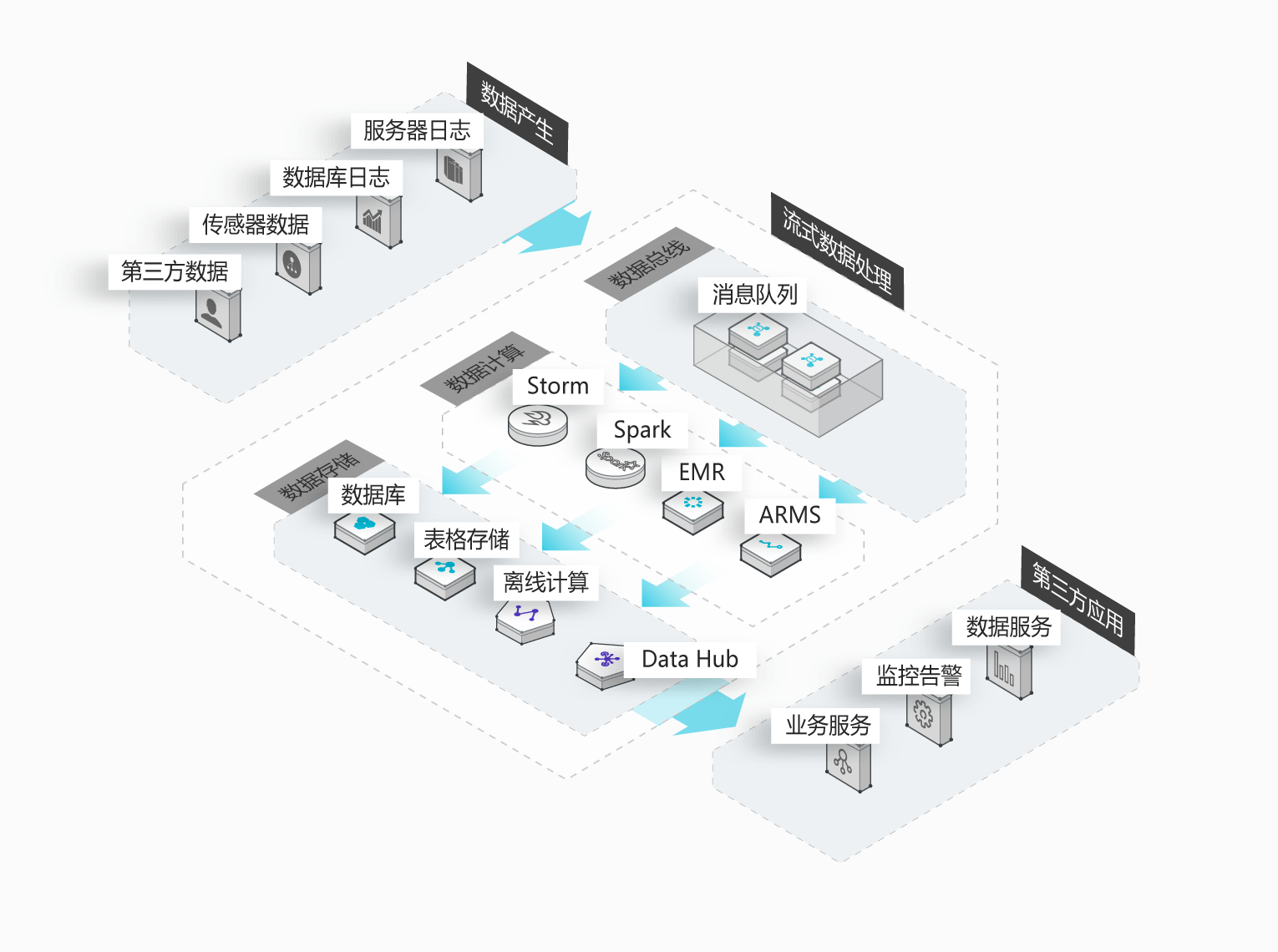
数据在"流动"中产生价值,传统数据分析大多是基于批量计算模型,而无法做到实时的数据分析,利用 RocketMQ /Kafka与流式计算引擎相结合,可以很方便的实现将业务数据进行实时分析。
RocketMQ/Kafka-分布式模缓存同步
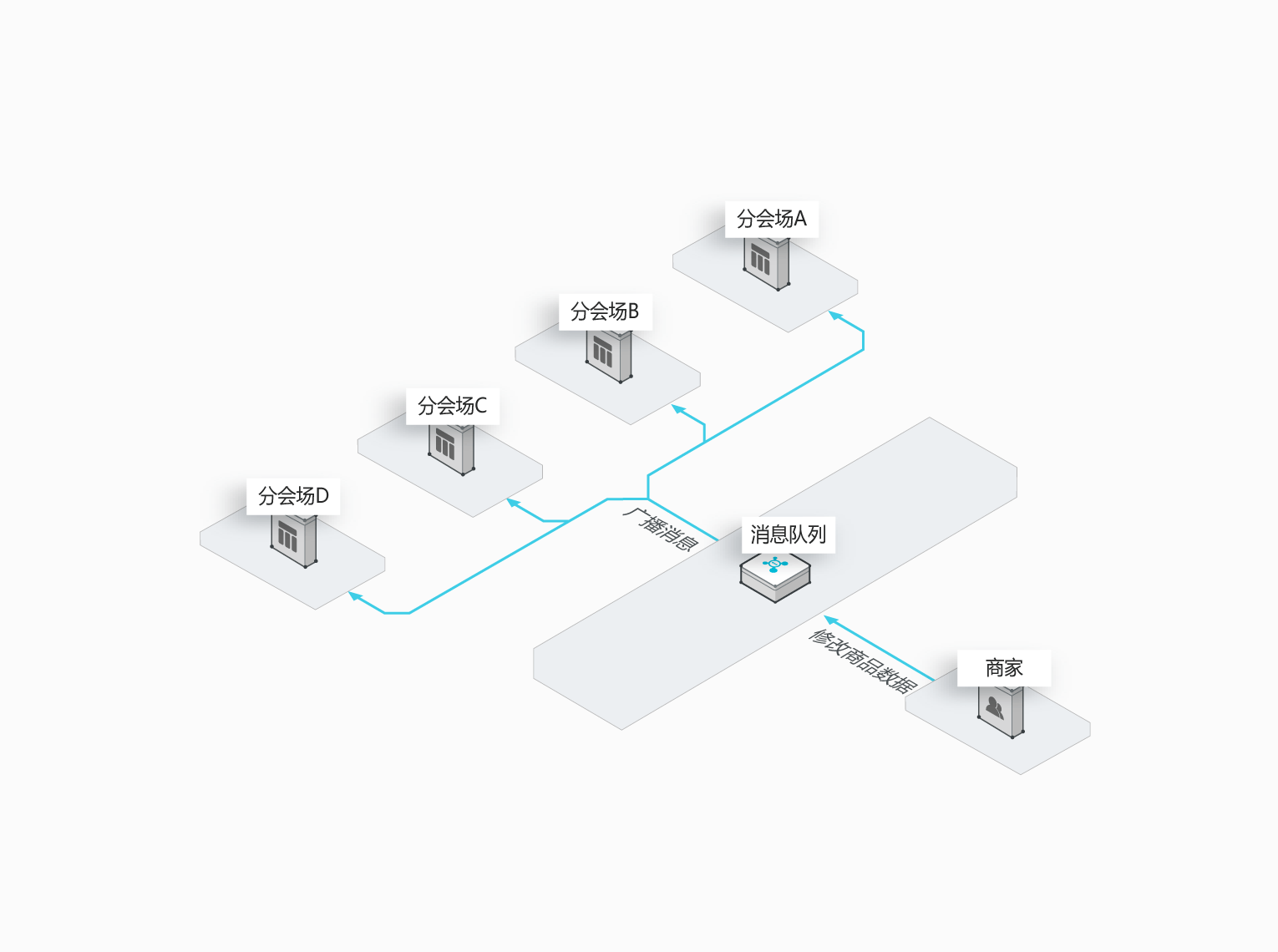
大型项目做了分布式缓存(分会场),各个分会场琳琅满目的商品需要实时感知价格变化,大量并发访问数据库导致会场页面响应时间长,集中式缓存因为带宽瓶颈限制商品变更的访问流量,通过 RocketMQ 构建分布式缓存,实时通知商品数据的变化。
大促众多分会场,多缓存的架构设计,满足对商品变更的大量访问需求。
2、为什么选用Redis缓存,MQ如何进行技术选型!
Redis有丰富的功能,不单纯是一个缓存。如果是对比的话,MongoDB的话缺乏Redis的功能,同时稳定性和版本的延续性对比Redis也要差不少。
MQ的话:
RabbitMQ吞吐量最少。RabbitMQ的语言兼容性最好(多语言API做的很好,C、Python等等语言都支持),
RocketMQ的话,适合电商(有丰富的电商的场景)、比如延时消息之类的。(语言对接只有Java好对接点)
Kafka适合于大数据系统对接,有很多大数据组件比如Flink都有比较好的Kafka对接API之类的(多语言API做的不错,C、Python等等语言都支持。
站在存储的角度,RocketMQ和Kafka天生持久化,RabbitMQ的话需要配置(配置持久化性能会有下降)。同时RabbitMQ需要去了解AMQP模型,RokcetMQ和Kafka模型简单。RabbitMQ消费是删除消息,RocketMQ和Kafka都是消费偏移量管理,适合于存储消息,做消息回溯之类的。
3、MCA项目中Redis与MQ的运用
这些具体内容我讲了一个大概,需要看视频内容。




